
 By Miguel Baez, Senior Threat Analyst
By Miguel Baez, Senior Threat Analyst
So, we’ve discussed the importance of implementing a Threat Intelligence Platform into your Security Operations Center (SOC) to support your daily Cyber Threat Intelligence (CTI) practice. And we’ve shared our method of reviewing disparate intelligence feeds to make sure they all align with your own Structured Threat Information Expression (STIX) data model, or what we call Source Crafting. But how do you determine what you want your organization’s data model to look like?
The STIX model (even 2.x) is very flexible and there is much room for interpretation. Analysts working on the same topic can easily create multiple different interpretations of the same data. This is a general problem. But it is particularly difficult in an environment where you work across multiple different feeds, each with its own interpretation of how the data should be structured.
This is why we at the EclecticIQ Fusion Center have decided to adhere to an agreed-upon data model if we are to scale across a breadth of feeds but retain sufficient depth of data for our intelligence to be usable.
Our Data Model
As it appears in STIX 1.2: 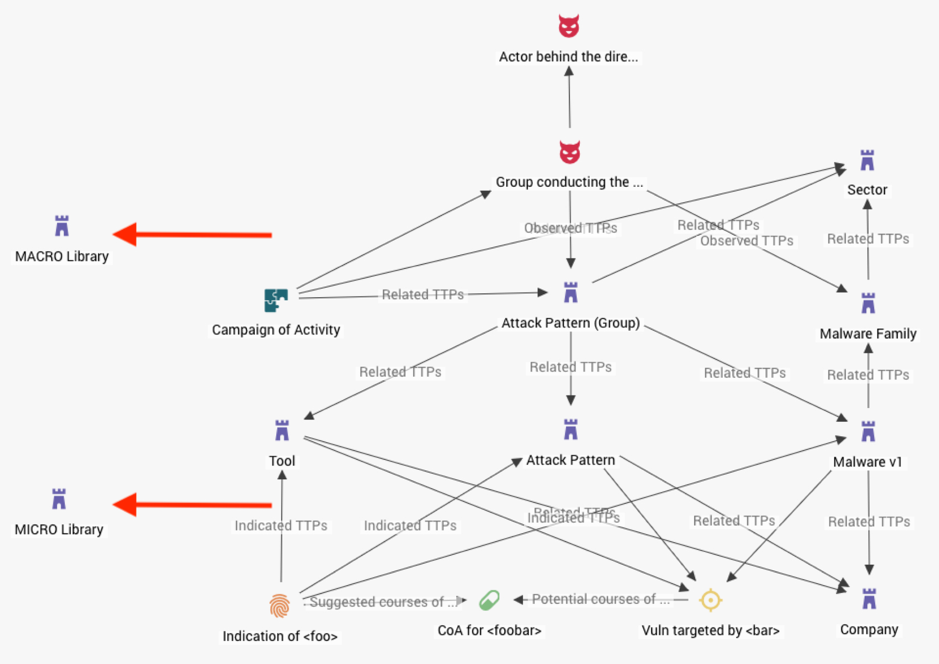
As it appears in STIX 2.1:
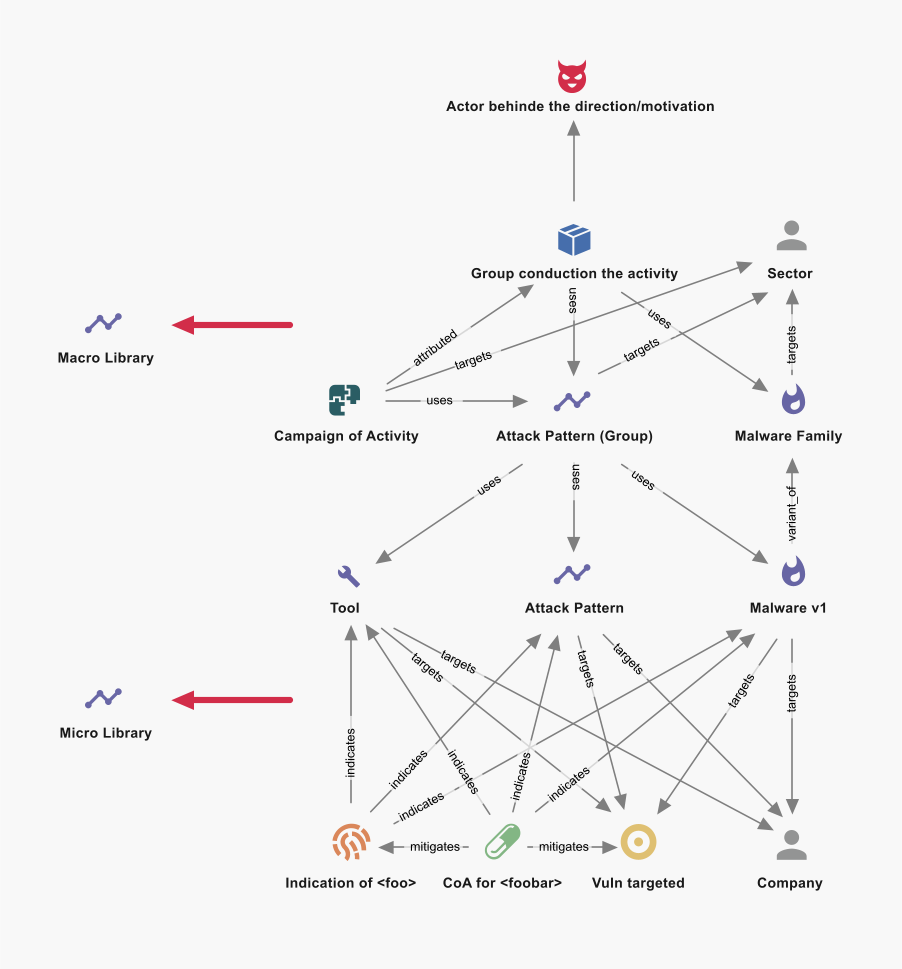
1→2 Entity Comparison
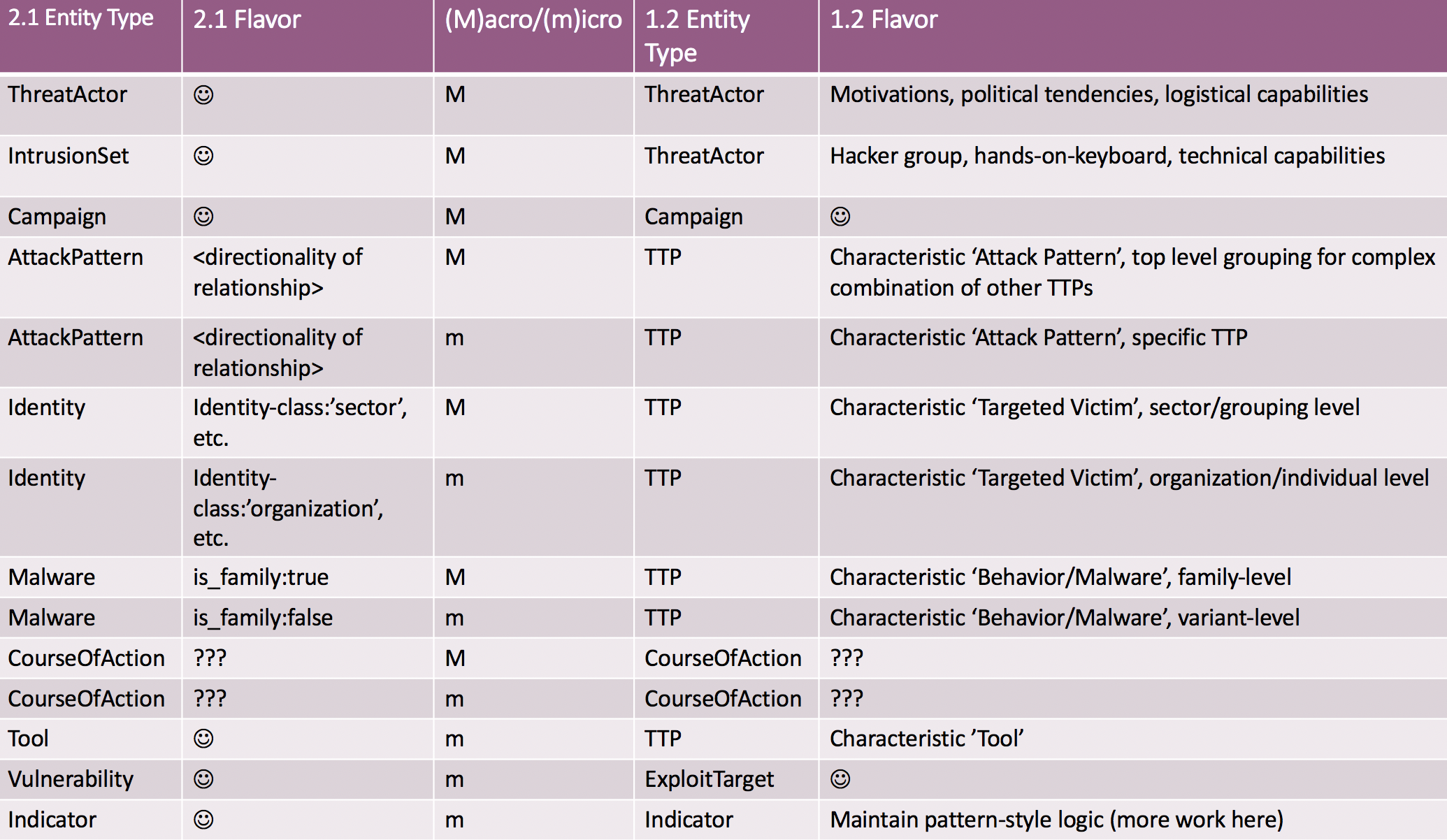
The two data models are designed to be semantically equivalent in order to allow conversion of STIX 1.2 to STIX 2.1 according to the following translation table (note that the only difference is the inability to relate 1.2 Course of Action (CoA) entities to the full range of other entities, as is possible in 2.1):
General Principles
Some of the general principles that we adhere to:
- Do not create relationships outside of this data model – if we need to, this should be a BIG DEAL! that is discussed and accepted/rejected as a team
- Directionality of relationship is just as important as the relationship itself
- Entities should be completely filled out, as key fields in 1.2 will be used to assert comparison to 2.1 entities
- Build libraries of ‘macro objects’ – preferably from existing open source libraries like ATT&CK or CAPEC
- Use ‘library’ objects as terminators in logic paths to decorate/describe the functionality of an entity using a common language
Use Cases
Below are some sample use cases of applying the data model and using appropriate naming conventions:
- Complex Malware: In this example, the Neuron malware has both client and server components that are capable of running independently. The same variant is used by IntrusionSet: Turla in two separate campaigns.
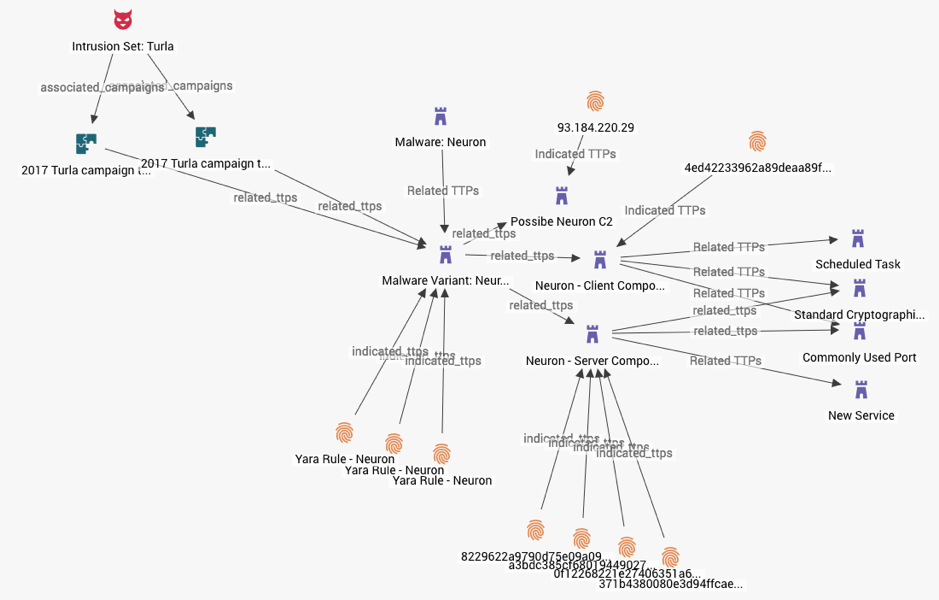
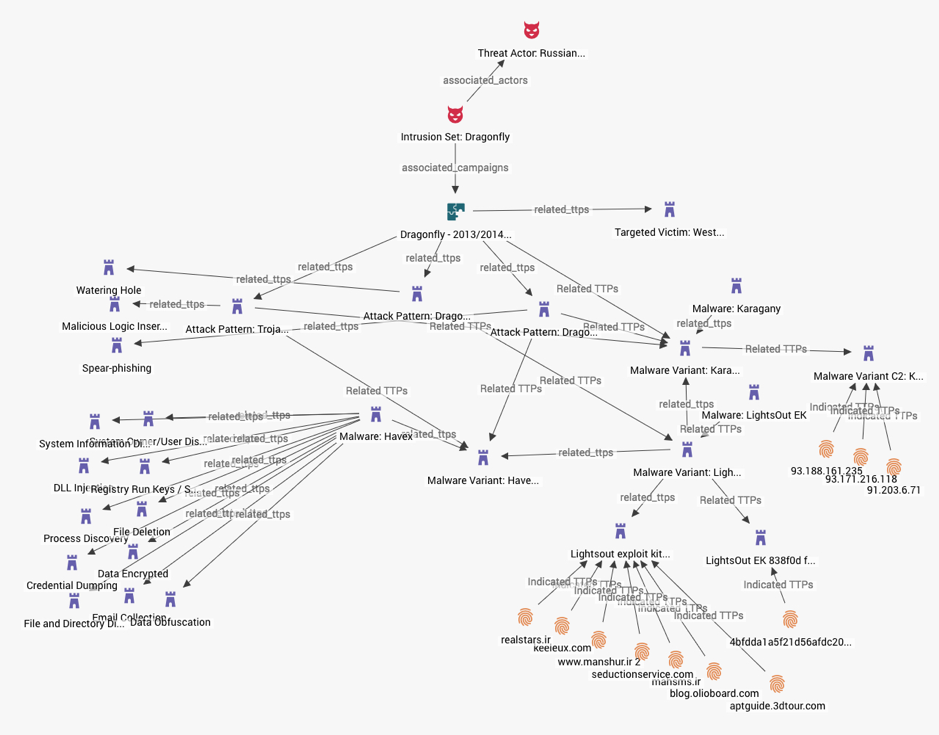
- Multiple-Attack Patterns: Here we see an Intrusion Set leveraging multiple Attack Patterns, each with unique malware, targeting the same ‘macro’ victim set.
Conclusion
Minimizing the room for interpretation in data sets is key for reliable CTI analysis. Especially, when working across multiple intelligence feeds, you want a data structure in place that prevents this major analyst headache. By adopting a data model such as the one outlined above, your organization can begin to ingest as well as produce consistent, usable, structured intelligence data. In a future blog post we will go into additional mitigation strategies that will help to reduce ambiguity, such as the opinion object in STIX 2.0.
We hope you enjoyed this post. Subscribe for more interesting reads on Cyber Threat Intelligence or check out our resource section for whitepapers, threat analysis reports and more.
