

In the summer of 2019, my friend Sergey introduced me to Natural Language Generation (NLG). He hypothesized that NLG could help threat analysts in writing finished intelligence products, and he wanted my help to prove (or disprove) his hypothesis. We soon realized that the full potential of NLG is vastly unexplored in the Cyber Threat Intelligence (CTI) space. In this blog, I want to provide a glimpse in our research and share the lessons learned. I will conclude with a personal view how analysts and NLG systems might complement each other in the future.
Turning Data Points into Intelligence
Organizations accumulate millions of IT data points each day. They collect events from host- and network-based security controls. Additionally, many organizations obtain some form of threat information daily - be it from open source feeds, from commercial intelligence providers or simply from the news. Yet, the final intelligence product - the document that is sent to the consumer - is often a written report by an analyst. With the influx of data, intelligence teams are confronted with challenges pertaining to data assessment & analysis, (near-) real-time creation of intelligence products, that are targeted at the right audience, all while operating at scale and with accuracy.
The Role of an Analyst
Before I continue how NLG can address some of the challenges, I must take a detour explaining the role of an analyst. This bypass is important to understand where NLG can support the analyst, and where its limitations are.
An analyst is paid to provide judgements on often fragmented information.* He or she must arrive to some sort of conclusion about a problem or a situation, and must tell the intelligence consumer what the facts (raw data, event logs, tables, matrices, graphs, news) mean. Or simply put, an analyst answers intelligence questions raised by consumers. Analysts write reports for a reason, and before they begin, they must answer the following questions, commonly referred to as the WHAT and the SO WHAT.
The WHAT?
An analyst must understand if there is development (a hook) that warrants a report. Answering the WHAT can also be driven by meeting a certain threshold, or by an event that departs from the norm. Think of a new zero-day vulnerability, an increase in failed-login attempts to an organization’s VPN, or new capabilities added to the latest ransomware.
SO WHAT?
An analyst must add something unique and provide judgments or insights that answer one or more of the consumers’ questions. He or she must point out why the event is relevant for reader. It is NOT the job of an analyst to repeat what other sources have already said, or to throw out background information in form of matrices, timelines, tables, graphs, and charts. An organization might be at risk because its assets are vulnerable to the zero-day and it is exploited in the wild. The failed logon attempts may indicate intensified reconnaissance due to a business merger that was recently announced by the CEO. The new ransomware capabilities cannot be detected by the Blue Team in-house.
Natural Language Generation - A Definition
Natural Language Generation is a branch of artificial intelligence and is the process of transforming structured data into text narratives. Contrary to Natural Language Processing (NLP) that reads and analyses textual data to derive analytic insights, NLG composes synthesized text through analysis of pre-defined structured data. NLG can be more than the process of rendering data into a language that sounds natural to humans. It can play a vital role in uncovering valuable insights from massive datasets through automated forms of analysis.
NLG Is Widely Adopted in Other Verticals
Implementation of NLG in other verticals has increased in recent years. We found early adoptions of NLG in a paper published in 1994 about a Forecast Generator (FOG). FOG produces text for weather forecast directly from weather maps. Unsurprisingly, major news outlets like The Washington Post, The Guardian, or Reuters leverage NLG to create tailored content for their readers. Also consulting companies use NLG to create reports for tax and accounting (Avisha Das, Rakesh Verma Department of Computer Science University of Houston, Houston, Texas, August 2019 - https://www.ta-cos.org/sites/ta-cos.org/files/4_W32.pdf).
From Structured Data to Narratives
Detailing the inner workings of NLG would go beyond the scope of this blog. However, the audience should know that NLG applications are based on three building blocks: The Document Planner, the Microplanner, and the Surface Realizer
The Document planner determines the context and decides what information should be communicated out of the full dataset available. It also defines how the information should be structured. The output of is a document plan object.
The Microplanner is responsible for
- Lexicalization: Choosing the words that will represent concepts
- Referring expressions generation: Selecting proper names, pronouns, and references
- Aggregation: Grouping information that should be expressed in one lexical block (a phrase, a paragraph, a section in the report)
The Microplanner creates a text specification object. The last building block is the Surface realizer, that generates the final text blocks from a text specification tree.
Narrator PoC
For our POC we choose to work with STIX >2 bundles. Structured Threat Information Expression (STIX™) is a language and serialization format used to exchange cyber threat intelligence (CTI).
We knew at the beginning that we would need high quality STIX2 bundles for meaningful results. With “high quality” we refer to:
- STIX objects that have their properties set (e.g. Threat Actor types, sophistication, primary_motivation)
- STIX objects that have meaningful relationships with each other, instead of being isolated objects. (e.g. a threat actor is linked to a campaign, that is linked to an attack pattern, that is linked to an indicator)
Sergey coded an NLG application that builds sentences describing the STIX properties and relations between STIX objects. Our focus was on producing routine factual sections of a document which humans often find monotonous to write. We experimented with different reports templates often used by analysts, e.g. a digest report, a timeline view, or a vulnerabilities report. For each template, the tool creates a different layout and generates simple sentences describing the STIX bundle. The image below shows a STIX bundle (right) and the sentences that have been generated and added to a draft (left). An analyst can then further edit the report.
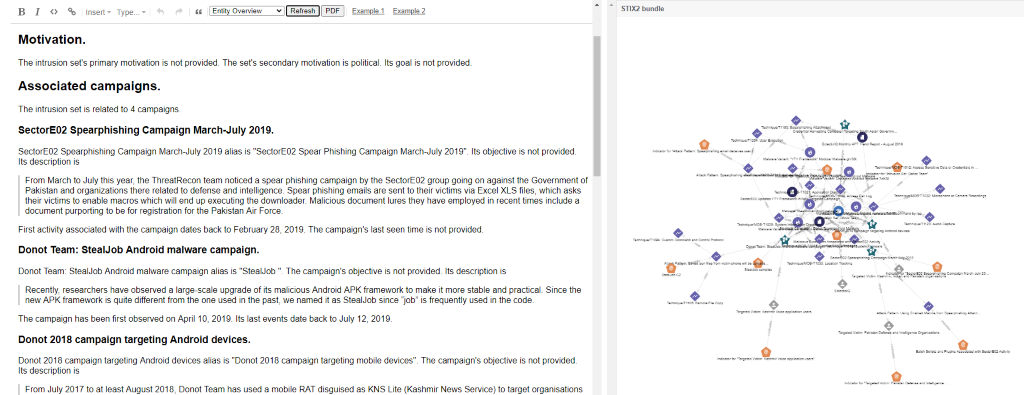
STIX bundle (right) and the sentences that have been generated and added to a draft
A video recording of the tool is available here.
NLG Can Support the CTI Analyst - If Done Right
We realize that our PoC only scratches the surface of the full NLG potential. We surely do not think it is ready to use in production. However, even our rudimentary results show that NLG can support analysts in content creation.
Automated Content Creation
With analysts already in short supply and having limited time available, it is not viable dedicating resources to a task that could be automated. Analysts spent a lot of time in conducting research, in identifying links, patterns, deviations from the norm and in documenting their evidences. Part of this research, which focuses on the WHAT, can be transferred to NLG. Not only can an NLG application find relevant information in big data sets, it will also prepare the information in a readable format that an analyst can then further work with.
Consistency & Conformance to Standards
Intelligence teams should adhere to some form of style manual or writers guide for intelligence publications. Such manuals dictate how analysts must organize their reports, how to structure sentences, what tense to use and much more. NLG can bake templates that follow the style manual, helping analyst to avoid common mistakes when writing reports.
NLG requires a Matching Use Case
For our rather simplistic PoC, we spent a lot of time in finding a matching use case which highlights one of the main takeaways. For NLG to work, intelligence teams must know what they want their data to tell them. The more targeted and specific the questions, the better the results. To diagnose its current situation and to create a vision of where the team is trying to get to, it should think about the following questions.**
Challenge: What challenges are you trying to solve?
Process: How can you translate this challenge into practical steps?
Data: Do you have the right data to solve the challenge?
Research: Where is the data coming from and how is it going to be vetted?
Pitfalls: What errors can be expected from the algorithm and how can you add oversight?
NLG Requires Significant SME and Engineering Investment
Generally, intelligences team do not have the time or the resources that allow for extensive research. A survey*** among journalists about artificial intelligence in the workspace, showed that engineers and subject matter experts can spent months reviewing report drafts, refining the story algorithms, and verifying the quality of the data supplied the NLG solution. The same would very likely be true for NLG in the CTI space.
Augmentation Rather Than Replacement
Remember the WHAT and the SO WHAT before writing a report? I believe that NLG can greatly help answering the WHAT. NLG is invisible fast and with the right algorithm it can identify trends, significant events and anomalies which are starting points for analysis. I see NLG will aid analysts through augmentation of tasks, such as translation, transcription, image search, augmented writing, and automated summaries.
At their best, NLG application can:
- Identify insights in big data. Detect a 100% increase of brute force attempts into a honeypot.
- Understand the importance of the insight. A 100% increase meets the threshold set by an analyst to deem the insight relevant.
- Deliver the insight to the analysts. NLG generates a text detailing WHAT has been observed along with supporting facts.
But NLG cannot explain the SO WHAT. What do all the collected facts mean? Why should an intelligence consumer be concerned about the increase in brute force attempts? I think interpreting the results and providing a judgment that is based on analytical techniques will remain the analyst´s responsibility.
Sources
*cf. David Cariens, Intelligence and Crime Analysis: Critical Thinking Through Writing, Shiplake House Publishing, 2011, p.41
**cf. Charlie Beckett, New Powers, New responsibilities - A global survey of journalism and artificial intelligence, LSE, November 2019, p.38 - https://drive.google.com/file/d/1utmAMCmd4rfJHrUfLLfSJ-clpFTjyef1/view
***cf. Beckett, p. 47-50
