
Now that we have launched EclecticIQ Platform release 2.8, we are excited to highlight some of the new features and functions to our analyst-centric threat intelligence platform (TIP). One of the significant updates is the way that the platform ingests and processes threat data. Consistently, our customers tell us that our ingestion process allows them to perform faster, better, and deeper investigations than with other TIPs. In release 2.8, we improve on this capability significantly.
Ingestion is more than simply storing input
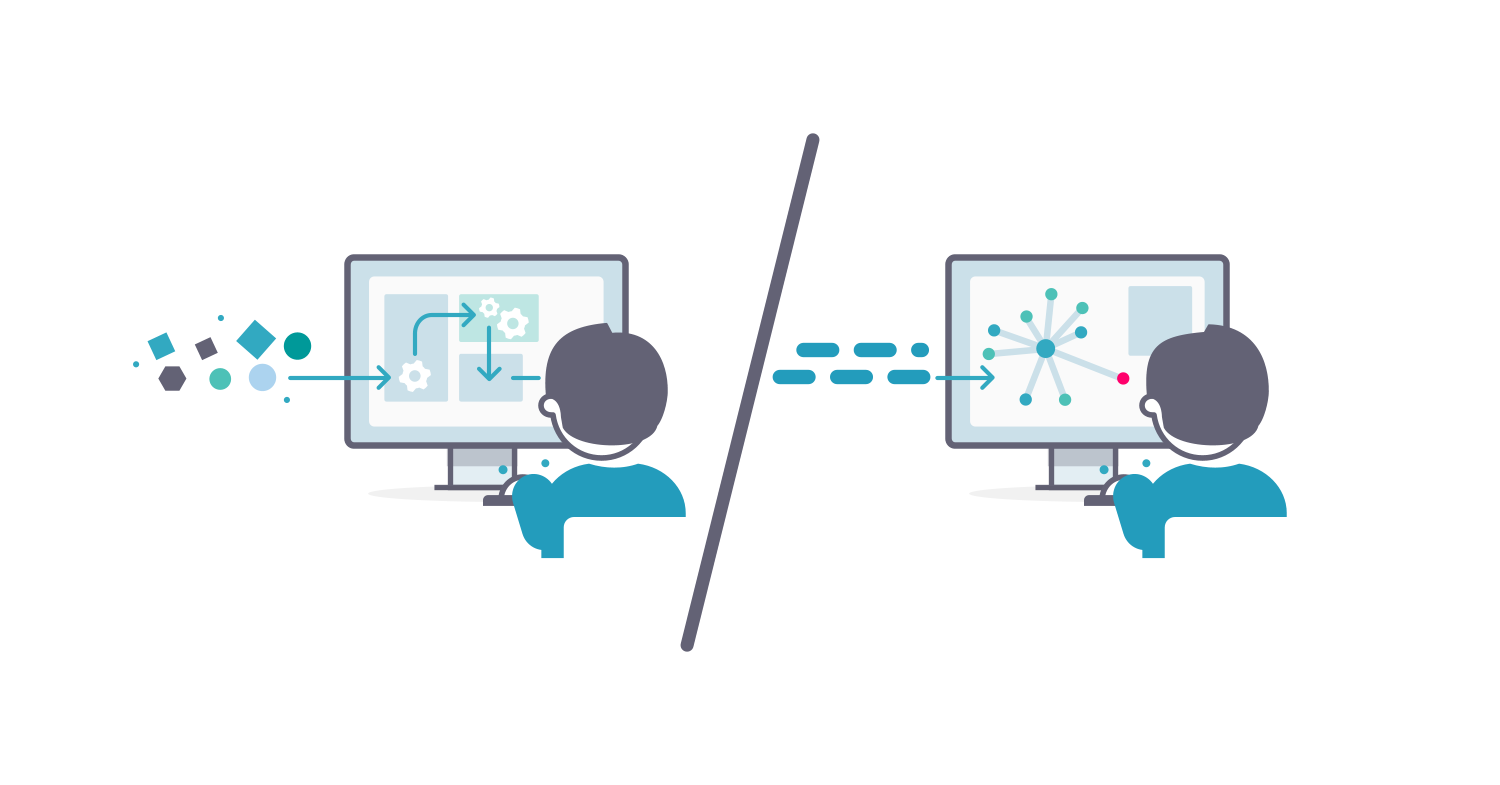
For successful threat intelligence operations, data must be as analyst-friendly as possible. After all, it is the threat intelligence analyst that depends on the TIP to do their job. In practice, delivering an analyst-friendly view requires significant data pre-processing during the ingestion process. This pre-processing involves ingesting and streamlining data, so users get a consistent and structured view, regardless of the original threat data source.
EclecticIQ’s ingestion includes a host of processes, including finding and removing duplicates across multiple feeds and tracking all references and relations in the process. And, ingestion transforms all kinds of entities (e.g. indicators, actors, malware, vulnerabilities, and attack patterns) and observables (e.g. IP addresses, hashes, URLs). Finally, ingestion applies user-defined rules to organize all this information to deliver useful content to the analyst (e.g. reports, graphs) with full-text search, and access controls, depending on the source. This ingestion pre-processing is an ongoing process affecting the customer’s entire knowledgebase, typically made up of millions of indicators, tactics, techniques, and procedures (TTP), threat actors, and so on.
There is no such thing as a free lunch
So, why do we do this? The benefit of our ingestion approach is we transform all data, so whatever investigation an analyst conducts, they immediately see actionable information. In comparison, other approaches do minimal ingestion processing, extracting only a subset of the data. This can make for faster ingestion, but weaker analysis. In other words, the upside of pre-processing is a more robust response, but the potential downside is the need for additional upfront compute power. If our customers can add CPU power in a predictable and scalable manner, then we believe the benefits of our approach far outweigh alternative approaches. However, delivering this level of scalability required us to make some key enhancements to our ingestion engine.
Shifting from package-based to entity-based ingestion
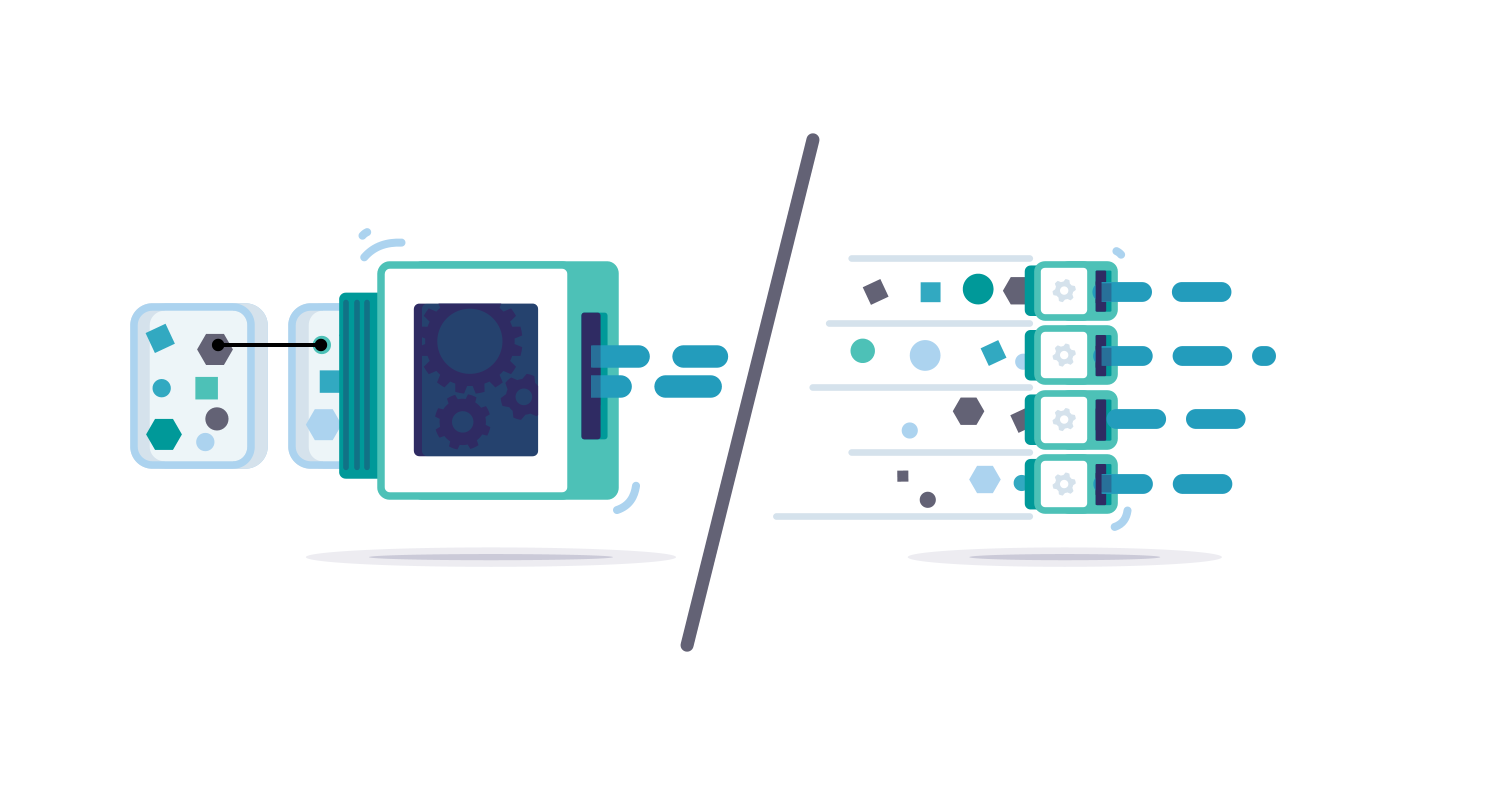
To process high volumes of data, we use parallel ingestion workers, and these workers need to coordinate to ensure data integrity. When we first built the ingestion engine five years ago, we expected most feeds would be structured (e.g. CybOX and STIX/TAXII). At the time, this was the direction that the market was heading. By design, each worker ingested an entire package before moving on. We expected that packages would be small and highly structured. Instead, feed data volumes are much higher, data is more highly connected (even across packages), and the packages themselves are larger.
Package-based ingestion takes locks for everything in the package, and everything to which the package refers. With the shift to big packages, highly connected data, high volumes, and many parallel workers, we have seen high lock contention situations negatively affecting ingestion performance.
We started addressing this potential ingestion performance issue in release 2.7 by introducing a new ingestion engine to balance processing time more fairly between different feeds. However, all processing was still on a package basis. Now, in release 2.8, we significantly improve the locking strategy by shifting from package-based ingestion to entity-based ingestion. With this shift, there is much lower lock contention leading to improved scalability.
Now, with release 2.8, adding more workers delivers a near-linear increase in throughput: adding more CPU processing means large feeds ingestion is faster than ever!
Cloud scalability with on-prem control and performance
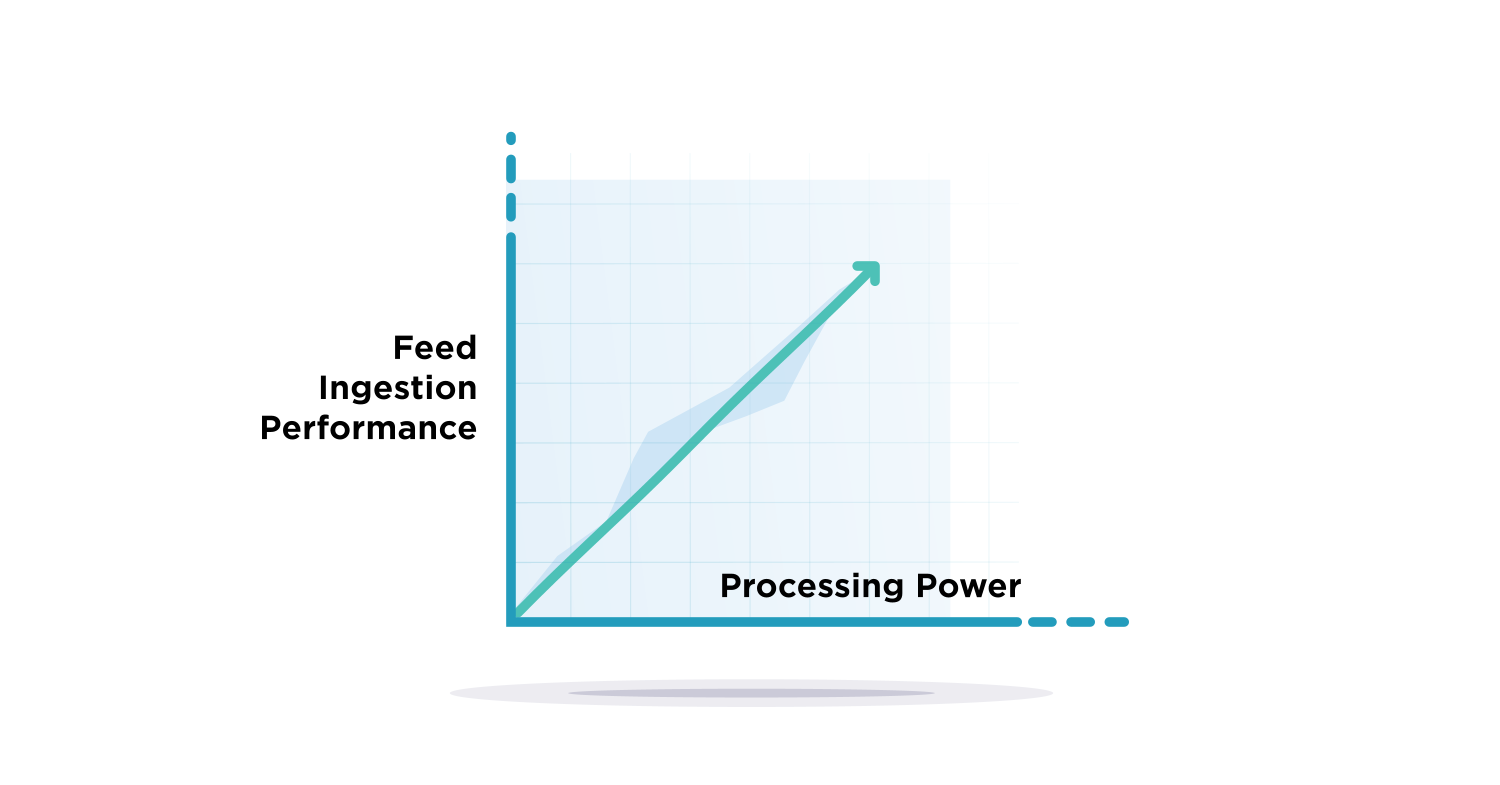
We are excited about release 2.8 and the updates to our ingestion engine. With this release, our customers can expect performance improvements with their current feeds. Also, new customers will see significant improvement at Platform startup. As customers add threat feeds (or their feed volume increases), they can add more processes with the ingestion performance scaling almost linearly.
With release 2.8, our customers can enjoy all the benefits of an on-prem TIP while achieving the scalability of a cloud-based system! We see this ingestion engine capability as a major improvement, and we plan to continue to add more performance and robustness with future releases.
Want to learn more?
If you would like to learn more about EclecticIQ Platform, please visit the product page or the blogpost on the latest release. Want to find out how EclecticIQ can strengthen your cyber defenses, please get in touch.
